与传统方案的对比
元数据路线:SBOM / GAV / 漏洞公告匹配
元数据路线的标准做法是:
- 解析项目构建文件(如
pom.xml),得到直接依赖与传递依赖; - 生成 SBOM 或直接维护“组件-版本”列表;
- 在漏洞数据库中查找“该版本是否受影响”。
这一路线优势明显:
- 扫描速度快;
- 实现和运维成本低;
- 适合大规模持续扫描。
但其边界也很清晰:
- 模块粒度问题:一个 CVE 常被绑定到整个项目,而真实影响可能只在某个模块,容易把“未受影响模块”也报出来(Spring Security的漏洞被标记为SPring框架的洞导致Spring Web MVC被报漏洞);
- 公告时滞问题:修复提交已经公开,公告还没更新时,会出现“代码已知可判定、但元数据尚不可判定”的空窗;
- 二次分发问题:重打包、重定位或移除元数据后,原始坐标信息弱化甚至消失,匹配链条断裂。
结论:元数据路线适合快速“粗筛”,但在 Java 修改依赖场景下精度和覆盖会显著下降。
源码路线:fix commit 与源码对比
源码路线(典型代表是代码中心扫描)通过 fix commit 提升判定精度,核心目标是回答“补丁是否已应用”。
与元数据路线相比,它的优点是:
- 可定位到真实修改代码,不只看版本号;
- 能区分“同版本不同状态”的组件;
- 理论上可减少版本标签误导导致的误报。
- 补丁回移,通过cherry-pick 把某一次提交移动到旧的标签前面保留旧的标签,实际漏洞已经修复;
- 二次编译
- 分发版版本体系差异
- 发布标签滞后
但在 Java 生态中会遇到一个结构性问题:
- fix commit 在源码层;
- 依赖交付在字节码层(JAR)。
一旦无法稳定获取与发布物一致的源码(或源码不可得),就会退化为 unknown、需要人工分析、可复现性下降。该问题在依赖经历修改(尤其重打包、重定位)后更加突出。
字节码路线:直接在发布形态上判定补丁状态
字节码中心路线把输入统一到“最终发布形态”。核心思想是:
- 不把“坐标可用”当作前提;
- 不把“源码可得且可信”当作前提;
- 直接在字节码层比较“漏洞前状态”和“修复后状态”的结构差异。
其关键收益是鲁棒性:
- 对重编译、重打包、去元数据天然更稳;
- 对 重定位 通过非限定名 + 上下文校验 + triplet 去限定化继续保持可判定能力。
背景
Java 依赖扫描的对象到底是什么
Java 项目可抽象为
:业务代码; :依赖集合(直接依赖 + 传递依赖)。
现实安全风险主要来自 D,原因有二:
- 依赖代码占比高,攻击面大;
- 依赖更新与漏洞修复节奏不完全可控。
传统扫描最容易忽略的一点是:真正上线运行的是“构建后的二进制集合”,而不是仓库里的声明文本。因此,“发布形态”比“声明信息”更接近真实风险面。
四类依赖修改及其二进制表现
重编译(re-compilation)
重编译指的是组件源代码在逻辑不变的前提下,被迁移到另一套编译环境重新构建并重新发布,这个过程中构建工具链(JDK 版本、编译器实现、插件、编译参数、调试信息开关)会改变字节码的组织细节和元信息,因此产物在“可执行语义”上与原版本一致,但在“二进制表现”和“指纹特征”上可能显著不同,最终导致依赖扫描若过度依赖原始构建指纹或源码到产物的强一致假设,会在同语义产物上出现匹配抖动。
1 | String greet(String n) { |
这段源码在 JDK 8 下通常会被编译为 StringBuilder.append(...) 链式拼接;在 JDK 9+ 下则常见为 invokedynamic + makeConcatWithConstants。两者行为等价,但字节码形态明显不同,这正是“重编译导致非语义差异”的典型场景。

图:同一份源码在不同编译环境下重编译后,字节码表现发生变化。
重打包(re-bundling)
重打包指的是将原本独立分发的多个依赖组件合并为单一 fat-jar 或 uber-jar 进行交付,这一过程通常通过构建插件把多份 class/resources 聚合到同一二进制中以降低部署复杂度,但代价是“组件边界从显式变为隐式”,即扫描器面对的是一个混合容器而不是清晰的一组件一工件结构,进而使基于坐标逐件判定的结果解释、责任归属和修复建议都变得更复杂。

图:多个独立 JAR 合并为单一 uber-jar 的过程。
重打包并去除元数据
这种方式是在重打包基础上进一步清理或剥离 pom.xml、META-INF、构建时间戳等可追溯元数据,目标往往是减小分发体积、统一发布规范或减少构建信息暴露,但结果是组件的来源、版本与模块身份不再在产物中显式呈现,扫描阶段只能更多依赖字节码本体去反推“它是谁、来自哪里、是否受某 CVE 影响”,从而显著削弱基于 SBOM/GAV 的直接判定链路。

图:重打包后继续剥离元数据,导致身份线索缺失。
重定位/重命名包路径(re-packaging)
重定位/重命名包路径是通过 relocation 规则系统性改写命名空间(例如把 com.lib.* 迁移为 vendor.shadow.com.lib.*)并同步重写内部类型引用的过程,其目的通常是解决依赖冲突和类加载隔离问题,但该操作会直接改变类与方法的全限定名,使大量依赖 FQN 建立索引的扫描方法丧失直连能力,即便核心逻辑与漏洞语义保持不变,也会因为“名称层不再对齐”而出现漏检风险。

图:命名空间 relocation 前后,FQN 与引用路径的变化。
由背景推导出的技术要求
要在上述场景稳定工作,扫描技术至少需要满足:
- 对“无元数据/错元数据”可退化运行;
- 对“无源码/源码不一致”可独立判定;
- 对“名称变化但语义保留”具备映射能力;
- 在可接受时间内完成项目级扫描。
字节码中心方案正是围绕这四条要求设计。
核心技术原理
总体架构:两阶段闭环
该技术由两个阶段组成:
- 阶段 A:知识库构建(离线,一次构建,多次复用);
- 阶段 B:依赖扫描(在线,对目标项目执行)。
阶段 A 产物是“可查询的漏洞知识库”,阶段 B 用它来判断目标 JAR 是否处于漏洞前状态或修复后状态。
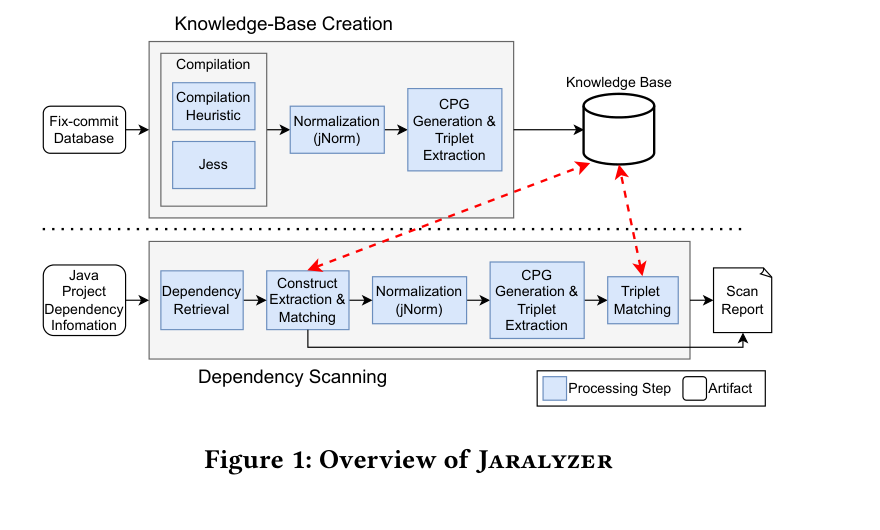
阶段 A:知识库构建
输入:fix-commit 数据库
输入数据形态是
常见的 fix commit 数据库来源包括:
Project KB:人工整理质量较高,工业场景常用;CVEfixes:从公开漏洞与代码仓自动挖掘,覆盖面较广;MoreFixes:在自动挖掘链路上进一步扩展,条目规模更大。
实际使用时通常需要按语言生态、数据质量和可编译性做二次筛选,避免把无效或噪声提交直接纳入知识库。
变更文件级编译(核心工程点)
直接编整个仓库成功率通常不高。该方案采用“只编译变更文件”的策略:
- 收集 fix commit 中被修改的 Java 文件(排除测试文件);
- 分别 checkout 到 pre-fix 与 post-fix 两个版本;
- 尝试提取 GAV,回溯 release tag 以找到可用构建补充(找到一个可用的发布版本提取依赖从而完成变更编译);
- 仅为变更文件准备编译所需依赖并编译;
- 启发式失败时回退 Jess;若 pre/post 仅一侧成功,会统一改用 Jess 以保持表示一致。
这一步的目标不是“还原完整仓库构建”,而是“稳定拿到可比较的变更字节码”。
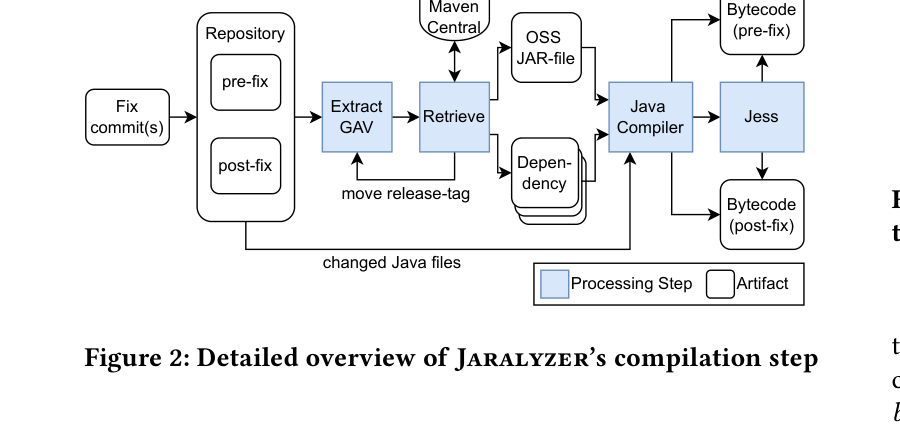
字节码归一化
即使源码一致,不同编译器版本、参数、目标平台也会引入非语义差异。归一化(jNorm)用于去除这类干扰,使后续比较聚焦于真正的补丁差异。
CPG 与 triplet 抽取
每个变更方法在 pre-fix / post-fix 分别生成 CPG(融合 AST、CFG、CDG、DDG)。
方法变更内容的求解是一个NP完全的子图同构问题,直接求解的时间复杂度是指数级的(O(n^k)),所以采用 triplet 近似:
- 每条边编码成
; - 得到 pre-fix triplet 集
与 post-fix triplet 集 。
进一步构造:
其中
最后把构件标识(FQN/非限定签名)、变更类型(ADDED/REMOVED/CHANGED)和 triplet 集写入知识库。
flowchart TB IN["输入: M_pre / M_post"] --> CPG["构建 CPG=(V,E)
V: 节点标签/类型
E: AST / CFG / CDG / DDG / ID"] CPG --> EXT["遍历每条边 e=(n_s,e_l,n_t)
提取 t=(label(n_s),e_l,label(n_t))"] EXT --> SETS["得到 T_vul 与 T_fix"] SETS --> CT["CT = T_vul ∩ T_fix"] SETS --> PT["PT = T_fix - T_vul"] SETS --> NT["NT = T_vul - T_fix"] CT --> KB["写入知识库:
identifier + diffType + CT/PT/NT"] PT --> KB NT --> KB
示例:从源码到 CPG,再到 triplet
下面用一个最小方法演示“源码 -> CPG -> triplet -> 集合差分”的完整链路。为便于阅读,这里使用简化节点模型(实际工具节点会更细)。
原始方法:
1 | int safeDivide(int a, int b) { |
步骤 1:节点抽取(示意)
| ID | 节点标签 |
|---|---|
| N0 | METHOD safeDivide |
| N1 | PARAM a |
| N2 | PARAM b |
| N3 | BLOCK |
| N4 | IF |
| N5 | COND (b==0) |
| N6 | RETURN 0 |
| N7 | ASSIGN c=a/b |
| N8 | RETURN c |
| N9 | ENTRY |
| N10 | EXIT |
步骤 2:在同一组节点上建立多种关系边
AST 边(语法结构):
N0 -> N1N0 -> N2N0 -> N3N3 -> N4N4 -> N5N4 -> N6N3 -> N7N3 -> N8
AST :
flowchart TB N0["N0: METHOD safeDivide"] N1["N1: PARAM a"] N2["N2: PARAM b"] N3["N3: BLOCK"] N4["N4: IF"] N5["N5: COND (b == 0)"] N6["N6: RETURN 0"] N7["N7: ASSIGN c = a / b"] N8["N8: RETURN c"] N0 --> N1 N0 --> N2 N0 --> N3 N3 --> N4 N4 --> N5 N4 --> N6 N3 --> N7 N3 --> N8
CFG 边(执行流):
N9 -> N4N4 -(true)-> N6N4 -(false)-> N7N7 -> N8N6 -> N10N8 -> N10
控制流图(CFG)示意:
flowchart LR
N9([N9: ENTRY]) --> N4{"N4: IF (b == 0) ?"}
N4 -- true --> N6["N6: RETURN 0"]
N4 -- false --> N7["N7: ASSIGN c = a / b"]
N7 --> N8["N8: RETURN c"]
N6 --> N10([N10: EXIT])
N8 --> N10
linkStyle 0,2,3,5 stroke:#ef4444,stroke-width:3px,color:#ef4444
CDG 边(控制依赖):
N4 -(true)-> N6N4 -(false)-> N7N4 -(false)-> N8
控制依赖图(CDG)示意(突出“谁控制谁执行”):
flowchart TD
N4{"N4: IF (b == 0) ?"}
N6["N6: RETURN 0"]
N7["N7: ASSIGN c = a / b"]
N8["N8: RETURN c"]
N4 -- true --> N6
N4 -- false --> N7
N4 -- false --> N8
DDG 边(数据依赖):
N2 -> N5(b进入条件判断)N1 -> N7(a进入除法表达式)N2 -> N7(b进入除法表达式)N7 -> N8(c的定义流向return c)
数据依赖图(DDG)示意(按“定义点 -> 使用点”表达):
flowchart LR N1["N1: PARAM a"] N2["N2: PARAM b"] N5["N5: COND (b == 0)"] N7["N7: ASSIGN c = a / b"] N8["N8: RETURN c"] N2 -- b --> N5 N1 -- a --> N7 N2 -- b --> N7 N7 -- c --> N8
步骤 3:从 CPG 边提取 triplet
对每条边
提取得到的全部 triplet(按边类型分组)如下:
flowchart LR
T["Triplet Set T(safeDivide)"]
subgraph AST["AST Triplets(8)"]
direction TB
A0["AST 全量"]
A0 --> A1["t1 = (N0: METHOD safeDivide, AST, N1: PARAM a)"]
A0 --> A2["t2 = (N0: METHOD safeDivide, AST, N2: PARAM b)"]
A0 --> A3["t3 = (N0: METHOD safeDivide, AST, N3: BLOCK)"]
A0 --> A4["t4 = (N3: BLOCK, AST, N4: IF)"]
A0 --> A5["t5 = (N4: IF, AST, N5: COND (b == 0))"]
A0 --> A6["t6 = (N4: IF, AST, N6: RETURN 0)"]
A0 --> A7["t7 = (N3: BLOCK, AST, N7: ASSIGN c = a / b)"]
A0 --> A8["t8 = (N3: BLOCK, AST, N8: RETURN c)"]
end
subgraph CFG["CFG Triplets(6)"]
direction TB
C0["CFG 全量"]
C0 --> C1["t9 = (N9: ENTRY, CFG, N4: IF)"]
C0 --> C2["t10 = (N4: IF, CFG_TRUE, N6: RETURN 0)"]
C0 --> C3["t11 = (N4: IF, CFG_FALSE, N7: ASSIGN c = a / b)"]
C0 --> C4["t12 = (N7: ASSIGN c = a / b, CFG, N8: RETURN c)"]
C0 --> C5["t13 = (N6: RETURN 0, CFG, N10: EXIT)"]
C0 --> C6["t14 = (N8: RETURN c, CFG, N10: EXIT)"]
end
subgraph CDG["CDG Triplets(3)"]
direction TB
G0["CDG 全量"]
G0 --> G1["t15 = (N4: IF, CDG_TRUE, N6: RETURN 0)"]
G0 --> G2["t16 = (N4: IF, CDG_FALSE, N7: ASSIGN c = a / b)"]
G0 --> G3["t17 = (N4: IF, CDG_FALSE, N8: RETURN c)"]
end
subgraph DDG["DDG Triplets(4)"]
direction TB
D0["DDG 全量"]
D0 --> D1["t18 = (N2: PARAM b, DDG, N5: COND (b == 0))"]
D0 --> D2["t19 = (N1: PARAM a, DDG, N7: ASSIGN c = a / b)"]
D0 --> D3["t20 = (N2: PARAM b, DDG, N7: ASSIGN c = a / b)"]
D0 --> D4["t21 = (N7: ASSIGN c = a / b, DDG, N8: RETURN c)"]
end
T --> A0
T --> C0
T --> G0
T --> D0
步骤 4:形成 triplet 集并做差分
- 修复前方法得到
; - 修复后方法得到
; - 交并差得到
。
例如补丁把 if (b == 0) return 0; 改成抛异常:
1 | int safeDivide(int a, int b) { |
对这个补丁,按上面的 triplet 定义可直接得到:
(旧 RETURN 0分支相关边被移除);(新 THROW分支相关边被新增);(其余结构保持不变)。
flowchart LR
R["Patch Diff Result(safeDivide)"]
subgraph NT["NT(4,移除)"]
direction TB
NTR["t6, t10, t13, t15"]
NT1["t6 = (N4: IF, AST, N6: RETURN 0)"]
NT2["t10 = (N4: IF, CFG_TRUE, N6: RETURN 0)"]
NT3["t13 = (N6: RETURN 0, CFG, N10: EXIT)"]
NT4["t15 = (N4: IF, CDG_TRUE, N6: RETURN 0)"]
NTR --> NT1
NTR --> NT2
NTR --> NT3
NTR --> NT4
end
subgraph PT["PT(4,新增)"]
direction TB
PTR["p1, p2, p3, p4"]
PT1["p1 = (N4: IF, AST, N6': THROW IllegalArgumentException)"]
PT2["p2 = (N4: IF, CFG_TRUE, N6': THROW IllegalArgumentException)"]
PT3["p3 = (N6': THROW IllegalArgumentException, CFG, N10: EXIT)"]
PT4["p4 = (N4: IF, CDG_TRUE, N6': THROW IllegalArgumentException)"]
PTR --> PT1
PTR --> PT2
PTR --> PT3
PTR --> PT4
end
subgraph CT["CT(17,不变)"]
direction TB
CTR["t1,t2,t3,t4,t5,t7,t8,t9,t11,t12,t14,t16,t17,t18,t19,t20,t21"]
CTA["AST: t1,t2,t3,t4,t5,t7,t8"]
CTC["CFG: t9,t11,t12,t14"]
CTG["CDG: t16,t17"]
CTD["DDG: t18,t19,t20,t21"]
CTR --> CTA
CTR --> CTC
CTR --> CTG
CTR --> CTD
end
R --> NTR
R --> PTR
R --> CTR
阶段 B:依赖扫描
依赖获取
扫描器通过构建工具解析目标项目依赖,并拉取待扫描 JAR/WAR。实现上可使用 Maven dependency:tree 与 copy-dependencies。
候选漏洞召回
候选召回的目标是先把“全量 CVE”快速缩小到“可能相关的少量 CVE”,再进入后续精判。
召回输入:
- 目标产物的字节码符号:类/接口/方法等构件的 FQN、非限定标识、包路径、构件边界信息;
- 阶段 A 知识库中的变更构件索引(来自 fix commit 抽取)。
知识库侧通常维护两类倒排索引:
- FQN 索引
: 构件 FQN -> {CVE, change, branch, 构件标识}; - 非限定索引
: 构件非限定标识 -> {CVE, change, branch, 构件标识}。
这里的“构件”统一指类、接口、方法等可匹配单元;“非限定标识”则按构件类型分别取:
- 类/接口:去掉包前缀后的简单名;
- 方法:去掉拥有者包路径与参数包前缀后的非限定签名。
召回流程:
- 默认模式(按构件 FQN)
从目标 JAR 提取全部构件的 FQN,在中查命中并并集化,得到首批候选 CVE。 - 重打包 / 重定位模式(按构件非限定标识)
当发生 relocation 或 fat-jar 混装时,构件 FQN 常失真,再提取同一批构件的非限定标识,到中召回补充候选。 - 候选合并
默认模式与重打包 / 重定位模式的候选集合求并,形成进入精判的最终候选池。
常见抑噪规则:
- 只保留与目标语言/生态一致的条目(如 Java 字节码);
- 设定最小命中证据门槛(如至少命中 1 个关键构件);
- 对高频通用符号(如
toString)降权,避免把大量无关 CVE 拉入候选池。
召回输出不是最终漏洞结论,而是“候选 CVE + 命中证据”:
- 候选 CVE ID;
- 命中的构件符号;
- 命中来源(FQN 或非限定标识);
- 对应的 change/branch 线索。
召回流程图:
flowchart TB IN["输入: 目标 JAR 中的构件集合
包含 FQN 与非限定标识"] subgraph D1["默认召回通道"] direction TB F1["提取构件 FQN"] F2["查询 I_FQN"] F3["得到默认候选 CVE 集"] F1 --> F2 --> F3 end subgraph D2["重打包 / 重定位召回通道"] direction TB U1["提取构件非限定标识"] U2["查询 I_UQ"] U3["得到补充候选 CVE 集"] U1 --> U2 --> U3 end M["候选并集"] N["抑噪过滤
语言一致性 / 最小证据 / 高频符号降权"] O["输出: 候选 CVE + 命中证据"] P["进入构件级与 triplet 级精判"] IN --> F1 IN --> U1 F3 --> M U3 --> M M --> N --> O --> P
构件级匹配规则
构件级匹配是阶段 B 的第一道精判门。每个知识库构件可抽象为:
其中 id 是构件标识(默认模式下通常为构件 FQN;重定位模式下可退化为构件非限定标识),diffType \in \{REMOVED, ADDED, CHANGED\}。
执行顺序:
- 用
id在目标产物定位同名/同签名构件。 - 按
diffType应用对应规则。 - 产出该构件的判定证据(漏洞证据 / 修复证据 / unknown)。
- 将构件结果交给后续“方法 -> change -> branch -> CVE”聚合。
三类规则的精确定义:
REMOVED:该构件在修复提交中被删除。若目标中仍存在该构件,记为漏洞证据;若不存在,记为修复证据。ADDED:该构件在修复提交中被新增。若目标中缺失该构件(且类上下文成立),记为漏洞证据;若存在,记为修复证据。CHANGED:同一构件前后都存在但内部逻辑变化。进入 triplet 判定(比较与 )后给出证据。
flowchart TB
S["输入: 构件 k=(id,diffType,CT,PT,NT)"] --> M["按 id 在目标产物定位构件"]
M --> T{"diffType ?"}
T --> R["REMOVED"]
R --> R1{"目标中仍存在该构件?"}
R1 -->|是| RV["记漏洞证据"]
R1 -->|否| RF["记修复证据"]
T --> A["ADDED"]
A --> A1{"目标中缺失该构件?"}
A1 -->|是| AV["记漏洞证据"]
A1 -->|否| AF["记修复证据"]
T --> C["CHANGED"]
C --> C1["进入 triplet 判定"]
C1 --> C2["输出漏洞/修复/unknown 证据"]
RV --> G["进入上层聚合"]
RF --> G
AV --> G
AF --> G
C2 --> G
示例(同一 CVE 的三个构件):
K1(REMOVED):legacyDivide(int,int)在修复后被删除。K2(ADDED):validateDivisor(int)在修复后新增。K3(CHANGED):safeDivide(int,int)从if (b==0) return 0;改为抛异常(triplet 规则与下节一致)。
| 构件 | 规则类型 | 目标 A(旧版本) | 构件结论 A | 目标 B(修复版本) | 构件结论 B |
|---|---|---|---|---|---|
legacyDivide(int,int) |
REMOVED |
仍存在 | 漏洞证据 | 不存在 | 修复证据 |
validateDivisor(int) |
ADDED |
缺失 | 漏洞证据 | 存在 | 修复证据 |
safeDivide(int,int) |
CHANGED |
triplet 更接近 pre-fix | 漏洞证据 | triplet 更接近 post-fix | 修复证据 |
构件级匹配并不直接给出最终 CVE 结论,而是先把每个构件转成可聚合证据,再由后续多层聚合做最终决策。
triplet 判定机制
对目标方法得到 triplet 集
常规判定思想:
- 若
,目标更接近修复前(漏洞状态); - 否则更接近修复后(修复状态)。
简单理解:应该被“减少/移除”的关系(
退化情形需要额外处理:
- 若
且 ,直接比较 与 即可。 - 若仅新增代码,则
,原判定式会退化为 0 >= |PT ∩ T_m|,因此需额外检查是否达到阈值 。 - 若仅删除代码,等价地考虑有
,判定逻辑也应该对称退化,此时从逻辑完备性看,也应要求 达到删除侧阈值 后,才可判为更接近修复前,但一般仅删除不仅仅只是会导致 ,同时也会新增边此时 所以一般不特别考虑。
下面给出常见情况的实际代码与计算过程。
情况 A:判定为漏洞状态(更接近修复前)
知识库(来自 safeDivide 补丁):
目标方法(待扫描):
1 | int safeDivide(int a, int b) { |
该方法的 triplet 集可写为:
交集计数:
判定结果:
- 因为
,扫描结论为漏洞状态。 - 实际状态:该代码仍是旧逻辑(
b==0时return 0),确实为漏洞状态。
情况 B:判定为修复状态(更接近修复后)
目标方法(待扫描):
1 | int safeDivide(int a, int b) { |
该方法的 triplet 集可写为:
交集计数:
判定结果:
- 因为
,扫描结论为修复状态。 - 实际状态:该代码已替换为抛异常分支,确实为修复状态。
情况 C:仅新增代码(
补丁示例(仍使用 safeDivide,只新增防护逻辑):
1 | // pre-fix |
对这类“仅新增防护特征”的补丁,知识库满足:
(对应 SecurityMonitor.hit新增调用在 AST/CFG/DDG 上的关键关系)
若配置阈值
目标是旧版本(未新增监控调用)
扫描结论:漏洞状态。
实际状态:确实未修复。目标是新版本(包含新增监控调用)
扫描结论:修复状态。
实际状态:确实已修复。
阈值敏感性说明(该类场景非常关键):
设得过大:容易把“已修复但只命中部分新增关系”的样本误判为漏洞状态(假阴性上升)。 设得过小:容易把“未修复但偶然命中少量新增关系”的样本误判为修复状态(假阳性上升)。 - 工程上通常通过验证集调参,在“漏报风险”和“误报成本”之间选取折中阈值。
多层聚合:从方法到 CVE
这部分的核心是:先在细粒度判断,再逐层汇总,避免单个方法噪声直接影响最终 CVE 结论。
- 方法/类构件级(最细粒度)
- 对每个受影响方法计算其
与 的关系,得到 漏洞态 / 修复态 / unknown。 - 这一层的输出是“方法判定结果列表”。
- change 级(同一修复提交内聚合)
- 一个 change 往往包含多个方法,按多数策略聚合:
漏洞票 > 修复票 -> change=漏洞态;修复票 > 漏洞票 -> change=修复态;
相等或证据太少 ->change=unknown。 - 这一层把“方法结果”压缩成“每个 change 一个结果”。
- branch 级(重点)
- 同一 CVE 可能在
1.5.x、2.0.x等多个维护分支分别修复,修复代码形态可能不同。 - 先在每个 branch 内独立聚合 change 结果,再得到该 branch 的总体状态。
- 然后做 branch 证据筛选(例如按上下文相似度/命中覆盖率):只保留与目标产物“足够像”的 branch,避免把不相关分支的结果混进来。
- CVE 级(重点)
- 仅对“通过 branch 筛选”的结果做最终汇总。
- 若通过筛选的 branch 结论一致,直接输出该 CVE 状态;
- 若仍冲突(既有漏洞态又有修复态),输出
unknown或进入人工复核。
示例(含 branch 级与 CVE 级完整推导):
- 某 CVE 有两个分支:
B1=1.5.x,B2=2.0.x。 - 扫描目标产物后得到方法级结果:
B1/C1:m1=漏洞态, m2=漏洞态->C1=漏洞态B1/C2:m3=漏洞态, m4=unknown->C2=漏洞态B2/C3:m5=修复态, m6=修复态->C3=修复态- branch 级聚合:
B1:C1=漏洞态, C2=漏洞态->B1=漏洞态B2:C3=修复态->B2=修复态- branch 筛选(按上下文相似度举例):
sim(B1,target)=0.82(保留,阈值设为0.60)sim(B2,target)=0.37(剔除)- CVE 级汇总:仅剩
B1=漏洞态,最终输出该 CVE 为漏洞状态。
flowchart LR
subgraph B1["Branch B1 (1.5.x)"]
direction TB
M1["m1: 漏洞态"] --> C1["C1: 漏洞态"]
M2["m2: 漏洞态"] --> C1
M3["m3: 漏洞态"] --> C2["C2: 漏洞态"]
M4["m4: unknown"] --> C2
C1 --> BR1["B1: 漏洞态"]
C2 --> BR1
end
subgraph B2["Branch B2 (2.0.x)"]
direction TB
M5["m5: 修复态"] --> C3["C3: 修复态"]
M6["m6: 修复态"] --> C3
C3 --> BR2["B2: 修复态"]
end
BR1 --> F{"branch 筛选
sim >= 0.60 ?"}
BR2 --> F
F -->|B1: 0.82 保留| K1["保留 B1"]
F -->|B2: 0.37 剔除| K2["剔除 B2"]
K1 --> OUT["CVE 最终结论: 漏洞态"]
重定位(re-packaging)专用机制
这是方案最关键的补强部分,因为 relocation 会系统性改写包路径,导致“名字对不上但语义没变”。
典型现象是:
- 知识库里记录的是原始 FQN(如
org.apache.commons.math.SafeMath); - 目标产物里变成了重定位后的 FQN(如
vendor.shadow.org.apache.commons.math.SafeMath); - 若仍按 FQN 精确匹配,候选召回和后续判定都会明显漏检。
示例:同一方法在重定位前后“拥有者路径变了,非限定签名不变”
| 对比项 | 重定位前(知识库) | 重定位后(目标产物) |
|---|---|---|
| 类 FQN | org.apache.commons.math.SafeMath |
vendor.shadow.org.apache.commons.math.SafeMath |
| 完整方法签名 | org.apache.commons.math.SafeMath.safeDivide(int,int) |
vendor.shadow.org.apache.commons.math.SafeMath.safeDivide(int,int) |
| 非限定签名 | SafeMath.safeDivide(int,int) |
SafeMath.safeDivide(int,int) |
flowchart LR KB["知识库: org.apache.commons.math.SafeMath.safeDivide(int,int)"] T1["目标: vendor.shadow.org.apache.commons.math.SafeMath.safeDivide(int,int)"] X["FQN 精确匹配失败"] UQ["去包前缀后: SafeMath.safeDivide(int,int)"] HIT["恢复候选命中"] KB --> X T1 --> X KB --> UQ T1 --> UQ UQ --> HIT
非限定匹配
由于 FQN 被改写,初筛改为非限定签名匹配(类名/方法名去包前缀)。
可把方法签名映射为:
例如:
org.apache.commons.math.SafeMath.safeDivide(int,int)
与vendor.shadow.org.apache.commons.math.SafeMath.safeDivide(int,int)
都映射为SafeMath.safeDivide(int,int)。
但非限定匹配会带来“同名碰撞”,即召回过多候选,因此必须接后续过滤。
类上下文校验
非限定名不唯一,容易误命中。为此引入类上下文:
- 比较候选方法所在类的兄弟方法/字段集合;
- 计算交集相似度;
- 只有超过阈值
才保留匹配。
常用定义:
其中
示例(同一个 safeDivide(int,int) 命中两个类):
| 候选类 | 上下文特征(示意) | 与知识库相似度 | 处理 |
|---|---|---|---|
SafeMath |
clamp(int), MAX_VALUE:int, safeDivide(int,int) |
0.82 |
保留 |
NumberUtil |
toString(), format(double), safeDivide(int,int) |
0.29 |
剔除 |
若设
triplet 去限定化 + 上下文门槛
Java 字节码中的类型引用通常是全限定名。重定位后即使语义一致,triplet 也会不同。解决方式是:
- 比较前对 triplet 的类型签名做去限定化;
- 先检查上下文 triplet 命中率是否超过
; - 通过后再做正负 triplet 判定。
这里的“triplet 相似度/命中率”不是“两个方法整体语义相似度”的直接计算。
在本文流程里,核心是看目标方法
高:说明该候选方法与漏洞补丁上下文结构足够一致,可以进入下一步精判; 低:多半是同名噪声,不进入后续 判定。
所以可以简单理解为:在重定位场景下,通常是“先看 triplet 集合与
triplet 去限定化可表示为:
其中 deq(.) 表示移除包前缀,仅保留语义关键部分(类/方法简单名、操作类型等)。
然后计算上下文命中率:
- 若
:认为该候选只是同名噪声,直接丢弃; - 若
:再进入 判定。
示例:
- 已知某候选的
,且 ,则 ; - 设
,该候选通过门槛; - 继续计算得
,最终判为更接近漏洞前状态。
重定位专用机制的完整流程如下:
flowchart TB
subgraph P1["阶段 1:重定位召回"]
S["输入: 目标重定位产物"]
R1["非限定签名召回"]
R2["得到候选类/方法集合"]
S --> R1 --> R2
end
subgraph P2["阶段 2:类上下文过滤"]
C1{"sim_CC >= θ_CC ?"}
D1["否: 剔除候选"]
T1["是: 提取目标方法 T_m"]
C1 -->|否| D1
C1 -->|是| T1
end
subgraph P3["阶段 3:triplet 过滤与精判"]
T2["triplet 去限定化 uq(T_m)"]
G1{"ρ_CT >= θ_CT ?"}
D2["否: 剔除候选"]
J1["是: 计算 |NT∩T_m| 与 |PT∩T_m|"]
O["输出: 漏洞态 / 修复态 / unknown"]
T2 --> G1
G1 -->|否| D2
G1 -->|是| J1 --> O
end
R2 --> C1
T1 --> T2
这三步组合,实质上是在“召回能力”和“误报控制”之间建立可调平衡:先放宽名称限制保召回,再用上下文和 triplet 门槛收敛误报。
复杂度与运行效率的工程取舍
该方案比纯元数据扫描重,但通过以下策略压缩了开销:
- 候选召回先行,避免全量 CVE 全量比对;
- 仅对关键构件生成 CPG/triplet;
- 默认模式与重打包模式可按需组合执行。
总结
本文围绕“发布形态优先”的依赖漏洞检测思路,说明了如何从 fix commit 构建知识库,并在扫描阶段通过构件匹配与 triplet 判定识别漏洞状态。核心价值在于:当依赖发生重编译、重打包、去元数据与重定位时,仍能依靠字节码与结构关系保持较强判定能力。工程上通过候选召回、分层聚合、阈值门槛与上下文校验在召回与误报之间取得平衡,形成可落地、可解释的检测流程。

