漏洞描述 该漏洞是由于Tomcat在验证文件路径时存在缺陷,如果readonly参数被设置为false(这是一个非标准配置),并且服务器允许通过PUT方法上传文件,
影响版本 11.0.0-M1 <= Apache Tomcat < 11.0.2
环境搭建 该漏洞只在大小写不敏感的操作系统下发生,故所有测试环境均基于Windows系统。Tomcat 9.0.97 版本,解压后下载地址 下载地址 web.xml文件,设置DefaultServlet的readonly属性为false,即对静态资源启动PUT方法以为ROOT APP添加静态文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <servlet > <servlet-name > default</servlet-name > <servlet-class > org.apache.catalina.servlets.DefaultServlet</servlet-class > <init-param > <param-name > debug</param-name > <param-value > 0</param-value > </init-param > <init-param > <param-name > listings</param-name > <param-value > false</param-value > </init-param > <init-param > <param-name > readonly</param-name > <param-value > false</param-value > </init-param > <load-on-startup > 1</load-on-startup > </servlet >
此时我们可以使用类似下面这样的请求在 ROOT APP中新增一个静态文件。
request 1 2 3 4 5 6 7 8 9 10 11 PUT /test.html HTTP/1.1 Host : localhost:8000Content-Type : text/plainContent-Length : 0Connection : close<html> <body> test </html>
这样请求体中的内容将被写入到 ROOT APP 的根目录下。
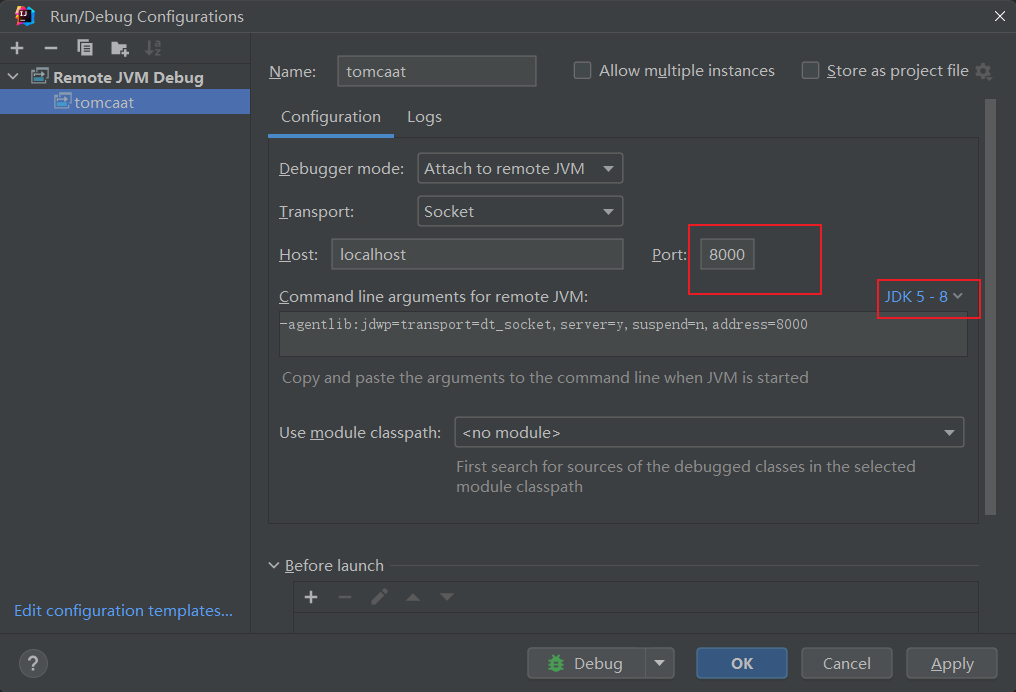
选择较低版本的JDK对tomcat进行启动,我这里使用的是8u202,因为较高版本的JDK规范化路径缓存默认是禁用的,而该漏洞需要这个选项开启。Tomcat根目录的/bin目录下执行以下命令启动tomcat并启动调试
启动后程序默认监听在8000端口
漏洞成因 这里我直接先介绍漏洞成因,以方便我对该漏洞进行说明。test.JSP的文件,然后在该文件没有正式落地的时候,通过GET请求访问test.jsp,在特殊的时机下静态资源文件test.JSP将被作为动态jsp文件解析,从而导致远程代码执行。test.JSP是被作为静态资源文件由DefaultServlet进行解析处理的,而test.jsp则是作为动态文件由JspServlet进行解析处理的,JspServlet只处理.jsp以及.jspx作为后缀的文件(JspServlet是大小写敏感的),而test.JSP或者test.Jsp这类文件都被认为是静态资源文件DefaultServlet处理。test.jsp,该请求是由JspServlet处理的,所以我们从JspServlet的serviceJspFile方法开始。jspUri即我们传入的test.jsp,这里跟进到getResource方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 private void serviceJspFile (HttpServletRequest request, HttpServletResponse response, String jspUri, boolean precompile) throws ServletException, IOException { JspServletWrapper wrapper = rctxt.getWrapper(jspUri); if (wrapper == null ) { synchronized (this ) { wrapper = rctxt.getWrapper(jspUri); if (wrapper == null ) { if (null == context.getResource(jspUri)) { handleMissingResource(request, response, jspUri); return ; } wrapper = new JspServletWrapper (config, options, jspUri, rctxt); rctxt.addWrapper(jspUri,wrapper); } } } try { wrapper.service(request, response, precompile); } catch (FileNotFoundException fnfe) { handleMissingResource(request, response, jspUri); } }
getResource方法位于org.apache.catalina.core.ApplicationContext.getResourcevalidateResourcePath方法首先检查path是否以/开头,如果以/开头则返回path,否则返回/加上path。StandRoot的getResource方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Override public URL getResource (String path) throws MalformedURLException { String validatedPath = validateResourcePath(path, !GET_RESOURCE_REQUIRE_SLASH); if (validatedPath == null ) { throw new MalformedURLException (sm.getString("applicationContext.requestDispatcher.iae" , path)); } WebResourceRoot resources = context.getResources(); if (resources != null ) { return resources.getResource(validatedPath).getURL(); } return null ; }
如果缓存允许缓存则从缓存中查找文件子资源。
1 2 3 4 5 6 7 8 9 10 11 protected WebResource getResource (String path, boolean validate, boolean useClassLoaderResources) { if (validate) { path = validate(path); } if (isCachingAllowed()) { return cache.getResource(path, useClassLoaderResources); } else { return getResourceInternal(path, useClassLoaderResources); } }
在noCache方法中指定了一些特殊的文件是不能缓存的,如:.class .jar 或者 classes目录下的文件等。resourceCache中根据请求的资源路径查找缓存资源,第一次访问时会返回null,即cacheEntry此时为null。CachedResource对象赋值给cacheEntry并调用其validateResource方法,进入该方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 protected WebResource getResource (String path, boolean useClassLoaderResources) { if (noCache(path)) { return root.getResourceInternal(path, useClassLoaderResources); } CacheStrategy strategy = getCacheStrategy(); if (strategy != null ) { if (strategy.noCache(path)) { return root.getResourceInternal(path, useClassLoaderResources); } } lookupCount.increment(); CachedResource cacheEntry = resourceCache.get(path); if (cacheEntry != null && !cacheEntry.validateResource(useClassLoaderResources)) { removeCacheEntry(path); cacheEntry = null ; } if (cacheEntry == null ) { int objectMaxSizeBytes = getObjectMaxSizeBytes(); CachedResource newCacheEntry = new CachedResource (this , root, path, getTtl(), objectMaxSizeBytes, useClassLoaderResources); cacheEntry = resourceCache.putIfAbsent(path, newCacheEntry); if (cacheEntry == null ) { cacheEntry = newCacheEntry; cacheEntry.validateResource(useClassLoaderResources); long delta = cacheEntry.getSize(); long result = size.addAndGet(delta); if (log.isDebugEnabled()) { log.debug(sm.getString("cache.sizeTracking.add" , Long.toString(delta), cacheEntry, path, Long.toString(result))); } if (size.get() > maxSize) { long targetSize = maxSize * (100 - TARGET_FREE_PERCENT_GET) / 100 ; long newSize = evict(targetSize, resourceCache.values().iterator()); if (newSize > maxSize) { removeCacheEntry(path); log.warn(sm.getString("cache.addFail" , path, root.getContext().getName())); } } } else { if (cacheEntry.usesClassLoaderResources() != useClassLoaderResources) { cacheEntry = newCacheEntry; } cacheEntry.validateResource(useClassLoaderResources); } } else { hitCount.increment(); } return cacheEntry; }
该方法首次调用时webResource为nullStrandardRoot的getResourceInternal方法中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 protected boolean validateResource (boolean useClassLoaderResources) { if (usesClassLoaderResources != useClassLoaderResources) { return false ; } long now = System.currentTimeMillis(); if (webResource == null ) { synchronized (this ) { if (webResource == null ) { webResource = root.getResourceInternal(webAppPath, useClassLoaderResources); getLastModified(); getContentLength(); nextCheck = ttl + now; if (webResource instanceof EmptyResource) { cachedExists = Boolean.FALSE; } else { cachedExists = Boolean.TRUE; } return true ; } } } ... }
该方法循环遍历allResources的所有元素并调用其getResource方法,直到扎找到资源为止。WebResourceSet为DirResourceSet。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 protected final WebResource getResourceInternal (String path, boolean useClassLoaderResources) { WebResource result = null ; WebResource virtual = null ; WebResource mainEmpty = null ; for (List<WebResourceSet> list : allResources) { for (WebResourceSet webResourceSet : list) { if (!useClassLoaderResources && !webResourceSet.getClassLoaderOnly() || useClassLoaderResources && !webResourceSet.getStaticOnly()) { result = webResourceSet.getResource(path); if (result.exists()) { return result; } if (virtual == null ) { if (result.isVirtual()) { virtual = result; } else if (main.equals(webResourceSet)) { mainEmpty = result; } } } } } ... }
DirResourceSet#getResource 方法中会调用file方法查找文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public WebResource getResource (String path) { checkPath(path); String webAppMount = getWebAppMount(); WebResourceRoot root = getRoot(); if (path.startsWith(webAppMount)) { ResourceLock lock = lockForRead(path); try { File f = file(path.substring(webAppMount.length()), false ); if (f == null ) { return new EmptyResource (root, path); } if (!f.exists()) { return new EmptyResource (root, path, f); } if (f.isDirectory() && path.charAt(path.length() - 1 ) != '/' ) { path = path + '/' ; } return new FileResource (root, path, f, isReadOnly(), getManifest(), this , lock.key); } finally { unlockForRead(lock); } } else { return new EmptyResource (root, path); } }
通过fileBase与name一起构造文件对象,这里name的值即我们传入的/test.jspgetCanonicalPath来获得文件的规范化路径。getCanonicalPath方法获取的规范化路径canPath是否与文件的绝对路径absPath相等,如果两者不想的则返回null,此时我们需要这两个值是相等的,canPath与absPath相等。跟进getCanonicalPath方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 protected final File file (String name, boolean mustExist) { ... File file = new File (fileBase, name); ... try { canPath = file.getCanonicalPath(); } catch (IOException e) { } ... absPath = absPath.substring(absoluteBase.length()); canPath = canPath.substring(canonicalBase.length()); ... if (!canPath.equals(absPath)) { if (!canPath.equalsIgnoreCase(absPath)) { logIgnoredSymlink(getRoot().getContext().getName(), absPath, canPath); } return null ; } return file; }
java.io.File.getCanonicalPathcanonicalize方法。
1 2 3 4 5 6 public String getCanonicalPath () throws IOException { if (isInvalid()) { throw new IOException ("Invalid file path" ); } return fs.canonicalize(fs.resolve(this )); }
useCanonCaches 表示是否启用规范路径缓存,也就是我们文章开头提到的高版本JDK这个值被设为false导致漏洞无法利用的原因。useCanonCaches的值必须为true,即我们希望进行规范化路径缓存。canonicalize0方法,这是一个native方法,具体的细节我就不再分析了,感兴趣可以查看参考链接 。canonicalize0方法有个特性,其规范的路径时不区分大小写的,即如果我要规范一个路径bastPath/test.jsp,basePath路径下查找是否存在test.jsp文件,如果此时basePath下不存在test.jsp文件,将basePath/test.jsp这个路径原样返回,basePath目录下存在test.JSP文件,则返回basePath/test.JSP,即规范路径时不区分大小写。.JSP结尾的静态资源文件当作动态文件解析了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 @Override public String canonicalize (String path) throws IOException { if (!useCanonCaches) { return canonicalize0(path); } else { String res = cache.get(path); if (res == null ) { String dir = null ; String resDir = null ; if (useCanonPrefixCache) { dir = parentOrNull(path); if (dir != null ) { resDir = prefixCache.get(dir); if (resDir != null ) { String filename = path.substring(1 + dir.length()); res = canonicalizeWithPrefix(resDir, filename); cache.put(dir + File.separatorChar + filename, res); } } } if (res == null ) { res = canonicalize0(path); cache.put(path, res); if (useCanonPrefixCache && dir != null ) { resDir = parentOrNull(res); if (resDir != null ) { File f = new File (res); if (f.exists() && !f.isDirectory()) { prefixCache.put(dir, resDir); } } } } } return res; } }
上面的方法执行完后会往cache中写入这样的键值对test.jsp -> test.JSP。file方法的时候出现问题了。basePath/test.jsp计算的canPath为basePath/test.JSP,计算的absPath为basePath/test.jsp,file方法将会返回null,这不是我们想要的。canonicalize0方法的时候说过其有一个特性是当basePath/test.jsp或者basePath/test.JSP等文件在文件系统中不存在的时候会原样返回basePath/test.jsp。file方法中得到的canPath就与absPath一致了,也就能正确返回File对象了。DirResourceSet#getResource方法,在成功调用file方法查找到文件资源后,调用f.exists()方法,检查文件是否存在,这是时候需要保证文件系统中存在文件basePath/test.jsp。Windows的文件系统中文件名是大小写不敏感的,所以basePath/test.jsp或者basePath/test.JSP其实表示同一个文件。test.jsp文件,但是可以创建test.JSP文件,因为该文件在Tomcat中是一个被当作一个静态资源文件处理的,我们可以通过PUT方法进行上传。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public WebResource getResource (String path) { checkPath(path); String webAppMount = getWebAppMount(); WebResourceRoot root = getRoot(); if (path.startsWith(webAppMount)) { ResourceLock lock = lockForRead(path); try { File f = file(path.substring(webAppMount.length()), false ); if (f == null ) { return new EmptyResource (root, path); } if (!f.exists()) { return new EmptyResource (root, path, f); } if (f.isDirectory() && path.charAt(path.length() - 1 ) != '/' ) { path = path + '/' ; } return new FileResource (root, path, f, isReadOnly(), getManifest(), this , lock.key); } finally { unlockForRead(lock); } } else { return new EmptyResource (root, path); } }
test.JSP文件的上传时机是非常重要的,我们需要canonicalize0方法调用完之前这个文件是不存在于文件系统的,否则缓存中保存的就是a.jsp -> a.JSP的映射关系,计算的canPath也变成了a.JSPabsPath与canPath的比较。 且要保证在f.exists调用之前test.JSP文件成功落盘,因为我们要保证文件存在否则将响应一个空的资源对象。
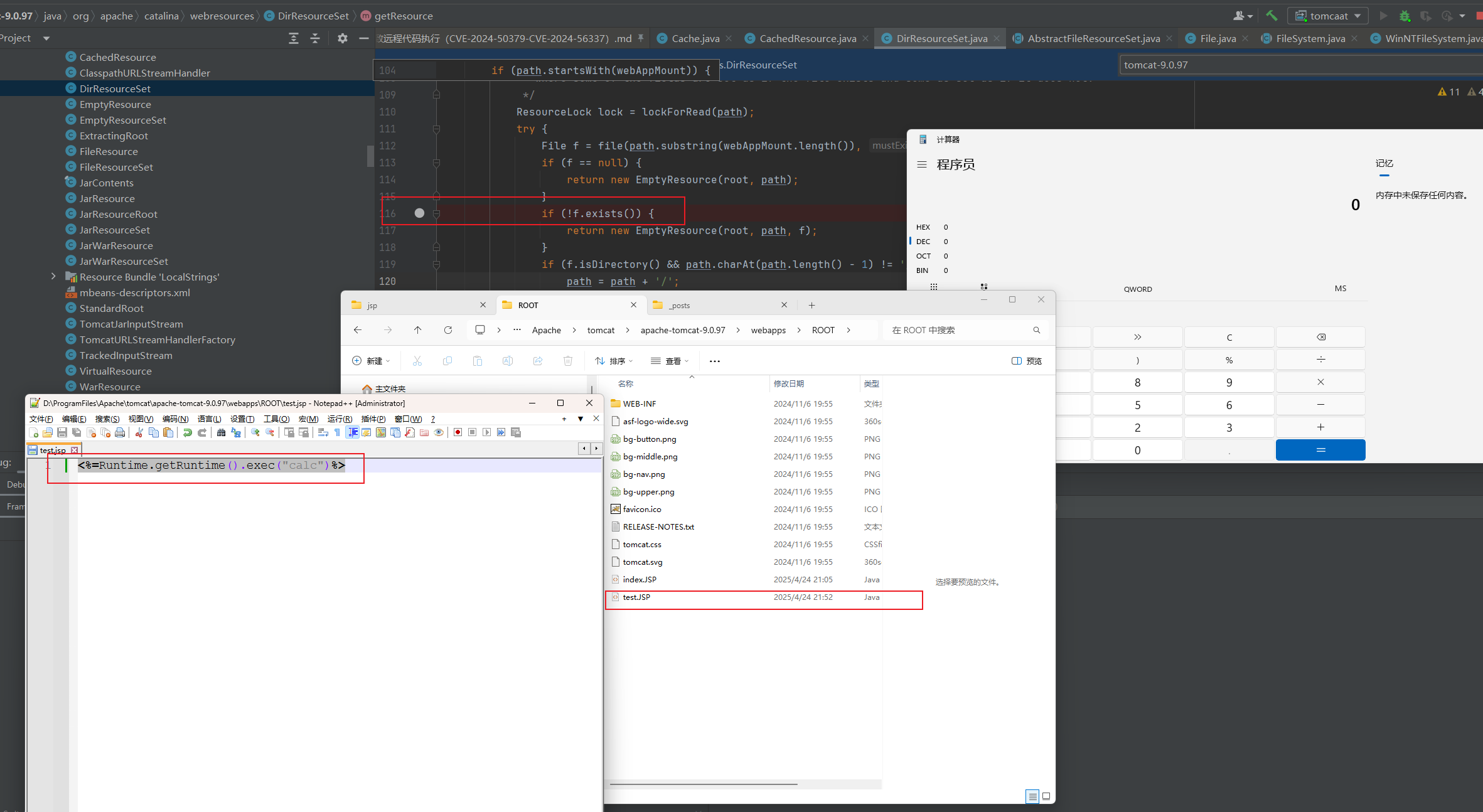
在调试环境下要做到这一点是非常简单的,我们只需要在f.exists这一行下断点,访问test.jsp运行到这一行时再到文件系统中创建test.JSP文件,然后让代码继续执行即可观察到test.JSP中的命令被执行了。
<%=Runtime.getRuntime().exec("calc")%>
实战环境下PoC的写法在了解了原理后相比并不困难(人比较懒),这里不再赘述。
参考链接